
He is the leader. She is the cleaner.
A Google Fordító szerint a férfiak okosak, főnökök, esznek, autót vezetnek, a nők buták, főznek és takarítanak. Vagy mondhatjuk kicsit másképp: a Google fordító szerint az, aki okos, főnök, stb., férfi, aki pedig buta, főz és takarít, az alighanem nő.
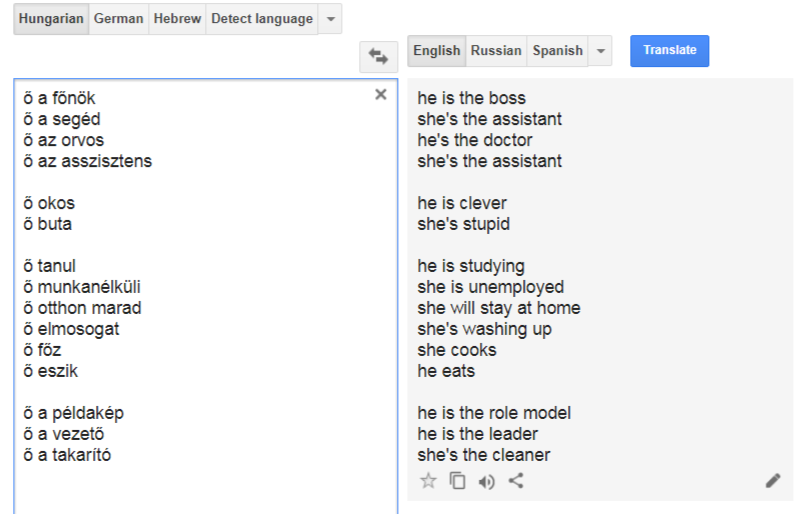
Amikor a Facebookon először megláttam a képet arról, hogy a Google Fordító egy szexista tulok, az első gondolatom az volt, hogy a screenshot biztos internetes vicc, net-népművészeti alkotás, mert ez 2017-ben nyilván nem lehet valódi.
De nem hagyott nyugodni, hogy valóban álhírről vagy viccről van-e szó. Ahogy egy barátom a maga finom szarkazmusával megjegyezte, „Őszintén szólva az első reakcióm az volt, hogy fake. Csodálkoztam is rajtad... :) De látom, a tőled megszokott alapossággal jártál el, és tényleg pofára esés.” Valóban percek alatt feltúrtam az internetet, hogy megértsem, valaki szórakozik (meglehet gonosz módon), vagy valami történik. Végül az derült ki, hogy egyik válasz sem helyes, csak a pofára esés a biztos. Nem valaki csinálta ezt, hanem valami, de az a valami legalább részben valaki, méghozzá mi, együtt, történelmi időkre visszamenően.
Hihetetlen, de egyáltalán nem újság
Mint sok más facebookos, twitteres fezúdulás és felfedezés esetében, a probléma nem új – persze a fake news korában már azt is meg kell becsülni, ha egy hír igaz, de régi. Nemcsak a gépi fordítás és a mesterséges intelligencia szakértőinek lehet ismerős, hanem a figyelmes újságolvasónak is, mert 2013-ban egy standfordi, 2017-ben pedig egy princetoni kutatás közzététele után bejárta a sajtót a gépi fordítók és a mesterséges intelligencia előítélet- és részrehajlásproblémája (pl. HuffPost , Guardian). Úgy tűnik, a mostani közösségimédia-kör kiindulópontja egy konferenciaelőadás “Stereotypes in Google Translate” feliratú diája volt egy női informatikusok közösségeként alapított társadalmi szervezet (1987-től Institute for Women and Technology, majd az alapító tiszteletére 2003-tól AnitaB.org) 2017. októberében tartott konferenciáján. A „Bias in AI: when you translate this from English ➡Turkish, a gender neutral language, then that same Turkish phrase back to English #GHC17” kísérőszöveggel a Twitteren terjedő képet rengetegen kedvelték és megosztották.
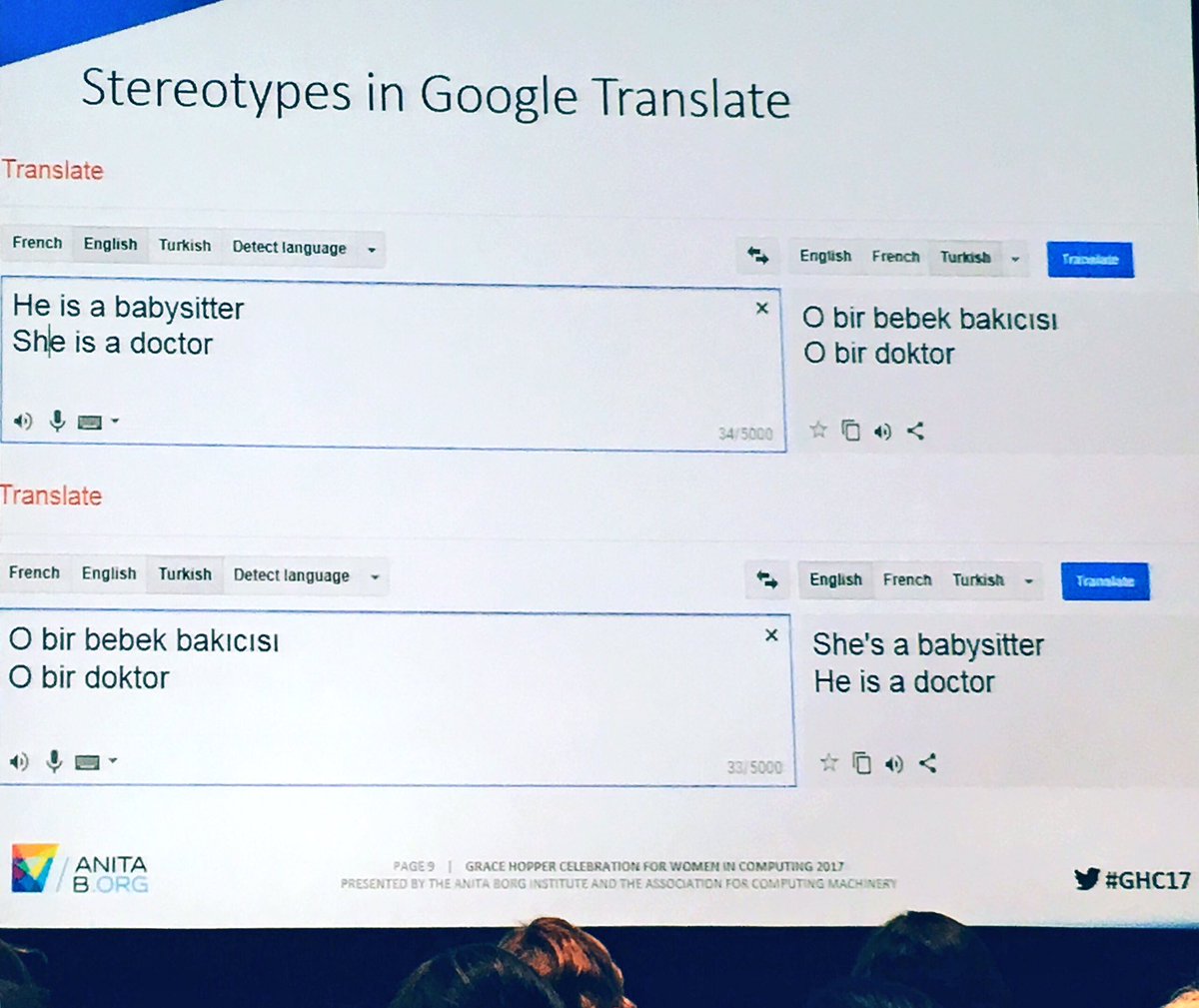
Ami különös, hogy ez az ezek szerint már jól ismert probléma ilyen régen fennáll -- már egyszer, többször tudtuk, mégsem történt semmi. Vajon miért?
A 2006 óta működő és havi több mint 500 millió felhasználót kiszolgáló Google Fordító nem úgy dolgozik, hogy válogat a szótári jelentések közül, és különféle szabályok szerint összerakja belőlük a célnyelvi mondatot. Empirikus módszerrel fordít; emberi erővel elkészített bonyolult szabályrendszerek helyett óriási példatárakat (korpuszokat) használ, és ezeket dolgozza fel. Kb. tíz évig statisztikai elemzés alapján a legoptimálisabb, legesélyesebb változatot választotta ki (ez az SMT, statisztikai alapú gépi fordítás).
Hogy is lesz akkor az „ő okos”-ból „he is smart”?
A Fordító mintákat keres több száz millió már lefordított dokumentumban, és ezek alapján próbál találgatni. Egy teljesen új nyelvpár sikeres bevezetéséhez kell egy minimum 1 millió szavas kétnyelvű korpusz (a két nyelv egymásnak megfelelő mondatpárjaival) és két egynyelvű korpusz (legalább 1 milliárd szó mindkét nyelvből), állította Franz Josef Och, a fordító egyik alkotója – a mágus, aki azóta már az élet meghosszabbításával és genetikai szűrésekkel foglalkozó biotechnológiai cégeket boldogít . Ilyen hatalmas korpuszok például az ENSZ és az EU több nyelven is publikált dokumentumai vagy a hírügynökségi szövegeket tartalmazó milliárdos nagyságrendű Gigaword korpuszok.
Ezt váltotta föl 2016-ban a neurális gépi fordítás, a tanulásra és fejlődésre képes mesterséges idegsejt-háló, ami kifejezések helyett már egész mondatokat dolgoz fel, a szavakat részekre bontja és ezeket a neurális hálózatban egyre inkább képes jelentésekké kombinálni, azaz nemcsak lefordítani, hanem érteni is, amit fordít. A mesterséges idegsejt-háló nem olcsó dolog – a Google Brain óriási anyagi befektetésére volt hozzá szükség, és még ez is csak egy viszonylag kicsi gépi agyat eredményezett, egy digitális egérkéét. A gépi deep learning segítségével fantasztikus fejlődést láttunk az elmúlt néhány évben, az unaloműző viccparádénak használt Google Fordító, ha nem is megbízható, de használható eszköz, elfogadható kompromisszum lett milliók számára.
Néha majdnem olyan jó, mint mi.
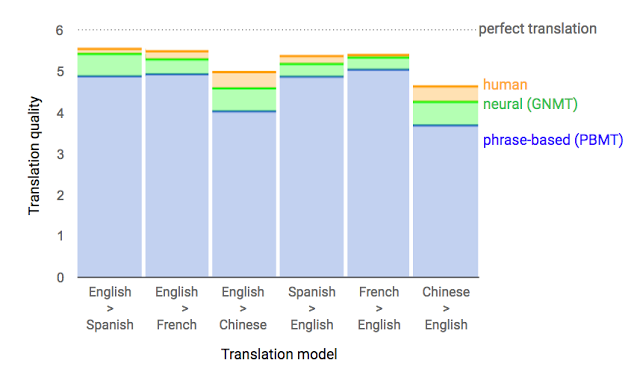
Forrás: Google Reearch Blog, 2016. szept. 27.
De ha ilyen okos, hogy lehet ennyire hülye?
Hogy maradhatott meg ebben a nagy hipermodern mesterséges agyban ez a mára kőkorszakinak számító, sértő és ostoba „tudás”? Ez volna a „deep” a deep learningben, hogy a legcsodálatosabb, még nemrég is elképzelhetetlen, varázslatos technológiával lemegyünk kutyába?
A statisztikai elemzés és a mesterséges intelligencia is mintákat keres a hatalmas adathalmazban és mindkettő ki van téve annak, hogy eleve részrehajló az információ, amit elemez és amiből tanul.
A hímnemű névmás azért a gépi fordítóprogramok defaultja, mert „a hímnemű névmás felül van reprezentálva azokban a nagy szövegkorpuszokban, melyekkel a modern rendszereket betanítják,” írja a 2012-es stanfordi kutatás vezetője, Londa Schiebinger.Tehát amikor a legvalószínűbb megoldást keresi a minták között, valószínűbbnek fog látszani ez a felülreprezentált változat. De bizonyos összefüggésekben a nőneműt választja, mert statisztikailag ő takarít, főz, vigyáz a gyerekekre, és (hogy valami jót is írjunk) csodálatos. Tehát a gépi fordító reprodukálja a korpusz öröklött részrehajlását.
Ráadásul a rendszer mostanáig csak az adott mondatot dolgozta fel, vagyis hiába derült ki az előző mondatokból, hogy férfiről vagy nőről van szó. A legelemibb kontextust nem tudta kezelni, de az összes rejtett részrehajlást megtalálta.
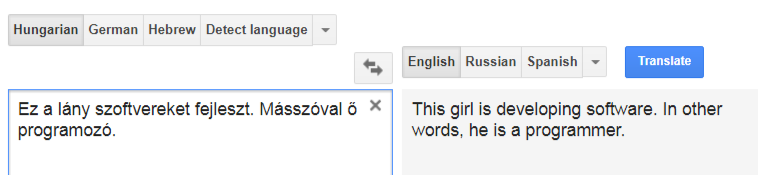
Ez is változik: idén augusztusban Helsinkiben egy neurális fordítórendszer átsettenkedett a mondathatáron! Elkezdték tesztelni, méghozzá az OpenSubtitles többnyelvű feliratain, hogy mi történik, ha a rendszer úgy tanul, hogy a szomszédos mondatokkal együtt kezeli a fordítandó mondatot. Ez alkalmas lehet arra, hogy jobban megfejtse és alkalmazza a nemre vonatkozó információt.
A statisztikai alapú hibás és sztereotíp módon elfogult fordítás csak egy példája annak, ahogy a mesterséges intelligencia megtanulja az adatok mintáiból az előítéleteket is. Ez a torzító hatás ráadásul meg is sokszorozódik, ha későbbi fordításoknál ezt az előfordulást is figyelembe veszik. Ha az orvos meg a programozó, meg aki nem főz, és nem takarít most férfi lesz a fordításban, a következő még inkább az lesz.
És miért nem lehet ezt olyan egyszerűen kijavítani?
Többek között azért, ami a mesterséges intelligencia nagy előnye: hogy nem definíciókra és szabályokra épül a működése. Sok, gyakran felfoghatatlan mennyiségű adatból megtanult kapcsolatokból, mintákból elég jó tippjei vannak, de nem tudja meghatározni, mi is az, amit tud. Bele lehet nyúlni az algoritmusaiba vagy felül lehet írni kézi szabályozással (pl. mindent tegyen hímnembe, mert még az is jobb mint ez a macsó viceházmester – állítólag ezt csinálták a héber igeragozással, amikor fellázadtak a felhasználók), de ez rontja a rendszernek azt a képességét, hogy azt is megtanulja – valóban rájöjjön -- amit mi nem tudunk. Az igazi megoldás tehát az lenne, ha a valóság lenne kevésbé szexista és azt tanulhatná meg. Addig azért az sem árt, ha az informatikusok sokat tanulnának a nyelv és az előítéletek összefüggéseiről és bizonyos esetekben korrigálnának azért, hogy a mesterséges intelligencia alkalmazása ne legyen egyenlő a már megvalósult emancipációs törekvések lenullázásával, a rossz hagyományok újraélesztésével.
Nekünk pedig fontos észben tartani, hogy a Google Fordító a szerencsés kivétel, ahol egy kis kísérletezéssel láthatóvá és kézzelfoghatóvá tehetjük magunknak és másoknak, hol „téved” a gép, de az egyre több helyen és funkcióban használt mesterséges intelligencia-alapú szolgáltatásnál, munkaügyi, biztosítási, orvosi procedúránál, amikor erre nincs és nem lesz módunk, ez ugyanígy elő fog fordulni. Nekünk kell arra gondolni, hogy mit is csinál valójában a fordító, a képelemző, a chatbot, a rákszűrés-ajánló, mikor belőlünk tanul.
Orbán Katalin




